개요
글 쓰기를 놓은 지 너무 오래되서 다시 습관을 재건(?)하고자 첫 타자로 OSI 모형 중 한 계층인 Transport Layer를 다뤄보려고 합니다.
네트워크는 웹 개발에 있어 너무나 중요하지만 항상 필요한 것만 보고 지나치느라 놓친 부분이 많았는데 이번에 놓친 부분을 채워보려고 합니다.
OSI 모형
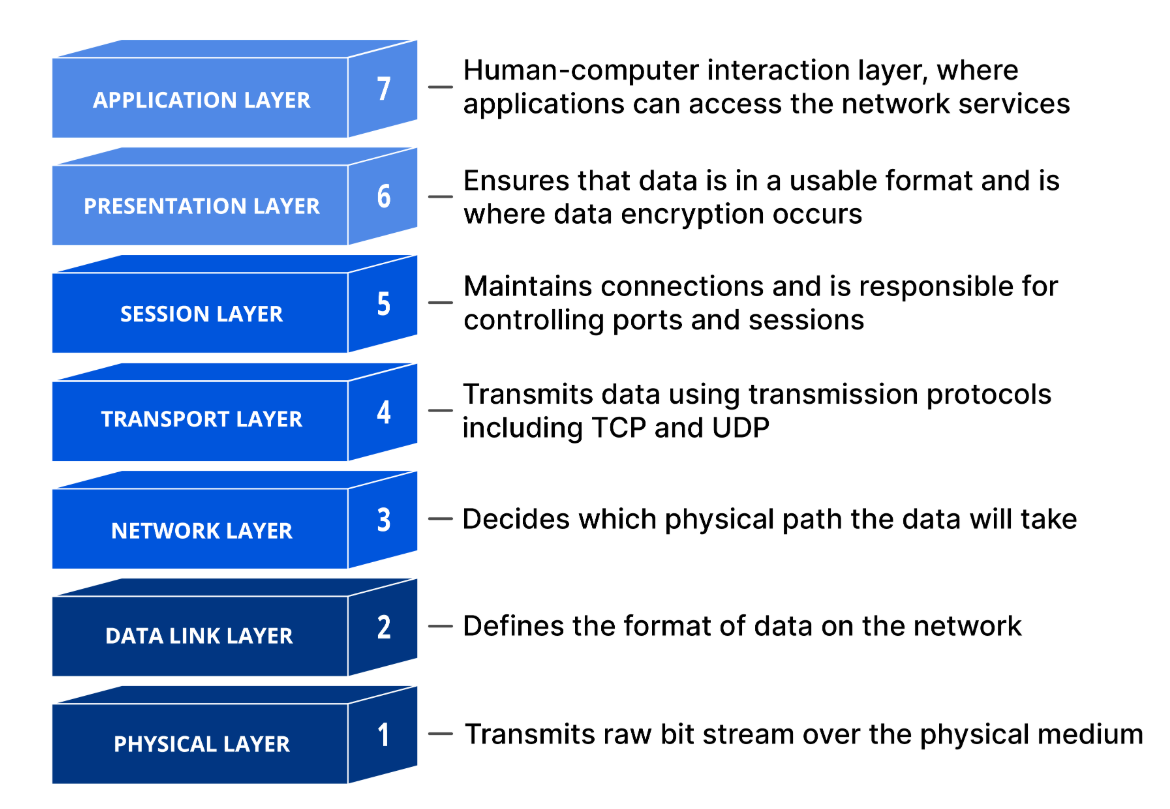
OSI 모형(Open Systems Interconnection Reference Model)을 가장 먼저 다루는 글이어서 짚고가면 좋을 것 같은데요, 이는 네트워크 통신 기능을 7개의 계층으로 나누는 개념적 프레임워크입니다.
왜 구분해 놓았느냐? 다양한 하드웨어 및 소프트웨어가 일관되게 작동해야 하여 네트워크를 통해 데이터를 전송하는 작업은 꽤 복잡한데, 이 네트워킹을 위한 ‘범용 언어’를 제공하여 다양한 기술이 통신 규칙을 사용하여 통신할 수 있게 만든 것이죠.
프로토콜과 인터페이스
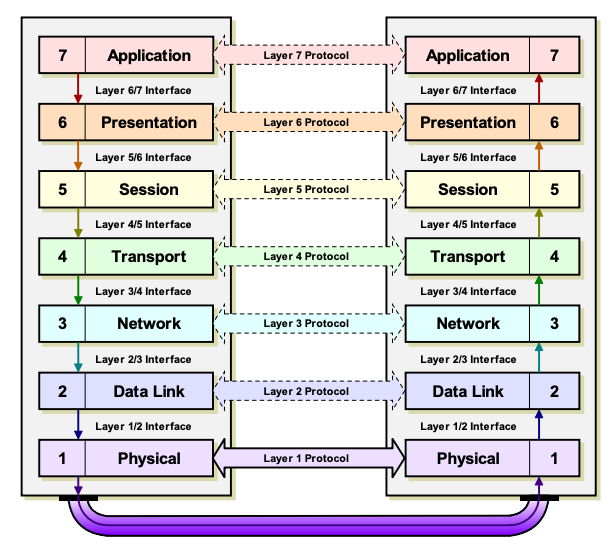
OSI 모델은 프로토콜(protocol)과 인터페이스(interface)라는 두 가지 개념을 사용하여 계층 간의 상호작용을 설명합니다.
그림을 살펴보면 L1으로 갈수록 하드웨어를 더 많이 다루며 추상화 수준이 낮아지고, L7으로 갈수록 소프트웨어를 더 많이 다루며 추상화 수준이 높아집니다.
프로토콜(protocol)
프로토콜은 장치 간 데이터 교환 또는 전송을 규제하는 일련의 규칙을 말합니다. 동일 계층에서의 논리적/물리적 장비 간의 통신하는 경우를 포함하죠.
여기서 프로토콜끼리 주고받는 메시지는 PDU(Protocol Data Unit)라 부르며, 각 PDU는 해당하는 프로토콜의 스펙을 구현한 포맷을 갖습니다.
이 PDU가 한 단계 아래 계층으로 전달되면 그 아래의 프로토콜이 서비스를 제공해야 하는 데이터가 되는데 이를 SDU(Service Data Unit)라고 부르죠.
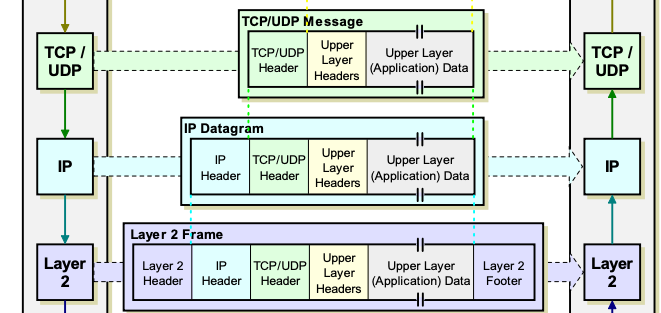
이렇게 한 계층에서 만든 PDU가 하위 계층에 SDU로 전달되어, 해당 계층의 서비스 목표와 포맷에 따라 다시 PDU로 캡슐화됩니다.
이 과정을 캡슐화(encapsulation)라 하며, 네트워크 데이터 전달의 흐름입니다.
인터페이스(interface)
인터페이스는 동일 장비의 위아래 인접 계층 간에 이동하는 정보를 나타냅니다.
예를 들어, 3/4 계층 인터페이스는 3계층과 4계층을 연결하는 정보를 나타내며, 이 인터페이스를 통해 4계층에서 생성된 PDU가 3계층으로 전달될 때 SDU로 전달됩니다.
The Internet That Wasn’t
초반부에 설명했지만 OSI 모형은 복잡한 네트워크를 부분으로 나누어 쉽게 이해하고 설계를 편하기 하기 위함이지, 모든 네트워크 기술이 OSI 모형에 완벽히 들어맞는 것은 아닙니다.
실제로는 OSI 모형을 고려하지 않고 설계되는 프로토콜도 있고 여러 계층에 걸쳐 있는 프로토콜도 있기 때문입니다.
이유가 무엇일까 찾아봤었는데, 이론적으로는 완성도 높은 참조 모델을 제시했지만 실제로는 구현과 배포가 늦어 시장과 기술의 변화를 따라가지 못했고 그 결과 OSI는 교육용 모델과 개념적 참조 틀로만 남았고, 인터넷은 TCP/IP 중심으로 성장했다는 배경이 있더군요.
이와 관련해서는 「OSI: The Internet That Wasn’t」 라는 글을 참고하면 좋을 것 같습니다.
Transport Layer(전송 계층)
이제 본격적으로 Transport Layer에 대해 알아봅시다.
OSI 모형에 따른 4번째 계층인 Transport Layer는 ‘종단 간(end-to-end) 통신’을 담당하며, 데이터의 신뢰성 있는 전송, 흐름 제어, 오류 검출 및 복구 등의 기능을 제공합니다.
이건 너무 사전식의 설명이라서 이어서 설명해보면, 전송 계층의 가장 큰 특징은 ‘논리적 통신’을 제공한다는 것입니다.
실제 인터넷 환경은 수많은 라우터와 링크를 거쳐 데이터가 전달되지만, 전송 계층 덕분에 애플리케이션 프로세스는 마치 통신하는 ‘호스트가 직접 연결된 것처럼’ 메시지를 주고받을 수 있습니다.
물리적 네트워크의 복잡한 구조를 알 필요가 없고, 오직 “상대방과 데이터를 교환한다”는 관점만 있으면 되는 것이죠.
가장 잘 알려진 프로토콜로 TCP(Transmission Control Protocol)와 UDP(User Datagram Protocol)가 있죠.
한 줄 요약하면 서로 다른 호스트에 실행되는 프로세스 간에 논리적인 통신을 제공하는 계층 이라고 볼 수 있습니다.
여기서 저는 왜 생겨났는지 궁금해져서 배경부터 알아봤습니다.
등장 배경

1957년, 소련이 세계 최초의 인공위성 스푸트니크 1호 발사에 성공하면서 미국은 큰 충격에 빠졌습니다.
소련이 미국보다 앞서 우주 개발에 성공했다는 사실도 충격적이었지만, 무엇보다 로켓 기술의 발전으로 미국 본토가 대륙 간 탄도미사일(한국인이라면 북한때문에 익숙한 단어인 ICBM)의 사정권에 들면서 핵 전쟁의 위험이 미국을 불안하게 만들었습니다.
핵 공격으로 인해 통신 시스템이 파괴된다면 국방과 관련된 모든 통신 수단이 마비된다는 두려움도 그 중 하나였죠.
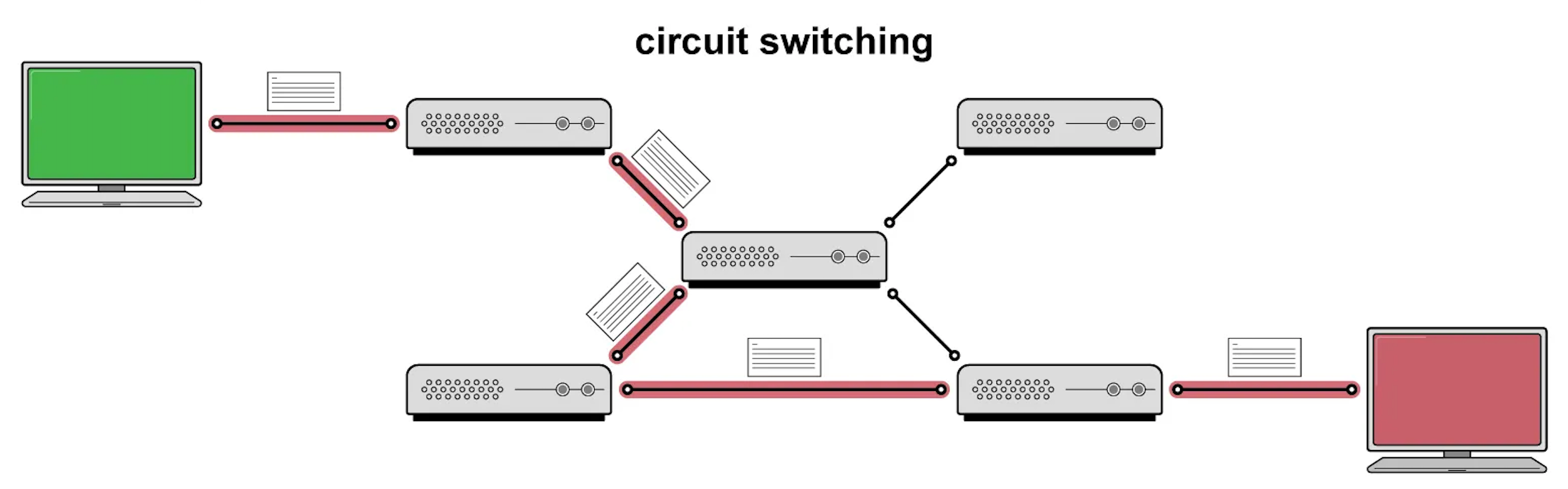
회선 교환 방식은 point-to-point 방식으로 연결되기 때문에 송신자의 모든 데이터는 동일한 경로로 전송하는데, 통신 중에 중간 경로에 문제가 생긴다면 전체 연결이 끊어져서 새로운 회선을 할당해야 하는 문제점이 있었습니다.
당시 미국에게 필요한 것은 핵폭발이 나더라도 통신할 수 있는 방법이 필요했기 때문에 하나의 회선에 의존하는 통신 방식은 대체가 필요했습니다.
패킷 교환 방식의 등장

이 때, 1960년대에 랜드 연구소의 폴 배런은 통신 핫 포테이토 라우팅이라는 개념을 고안했습니다. (뜨감?)
가능한 한 빨리 다른 자율 시스템으로 트래픽을 전달하여 해당 네트워크를 광역 전송에 사용하는 방식을 의미하며, 다음 절차를 따르도록 설계했는데요:
- 큰 메시지를 작은 디지털 정보 덩어리로 분할하고
- 각 덩어리에는 서로 다른 경로로 전송 가능하며
- 식별 헤더와 재조립 지침 포함하고
- 수신 측에서 원래 메시지로 재조립
모든 패킷이 저항이 가장 적은 경로를 따라 흐르도록 하여 디지털 데이터의 정체를 방지하는 방식이었죠.
이 방법은 처음에는 주목받지 못했지만, 영국 국립물리연구소(NPL)의 컴퓨터 과학자인 ‘도널드 데이비스`가 아이디어를 시험할 네트워크 실험을 시작하면서 다시 주목받았습니다.
미국 정부의 고등연구계획국(ARPA, 현 국방고등연구계획국[DARPA]) 의 관리자인 로렌스 로버츠는 1967년 10월에 개틀린버그 에서 열린 심포지엄에서 데이비스의 작업에 대해 알게 되었고, 로버츠는 자신의 차기 프로젝트인 ARPANET 에 데이비스의 용어인 ‘패킷 스위칭’을 채택했습니다.
이렇게 국방부에 채택되면서 ARPANET은 최초의 공공 패킷 교환 네트워크가 되었습니다.
그런데 당시 사용되던 기존 네트워크 프로토콜은 호환성이 낮고 확장성이 부족했으며, 데이터 전송 중 오류가 자주 발생하는 문제가 있었습니다.

그래서 1974년 빈트 서프 와 밥 칸은 논문 “A Protocol for Packet Network Intercommunication” 을 발표하면서 TCP 개념을 최초로 제안했고, 이는 서로 다른 네트워크 간의 통신을 가능하게 하기 위해 네트워크 계층과 전송 계층을 분리하여 TCP/IP 모델을 구상한 것입니다.
초창기 TCP는 데이터 패킷을 관리하는 역할뿐만 아니라 네트워크 라우팅도 포함하고 있었지만, 이후에는 IP(Internet Protocol)가 라우팅을 담당하고, TCP는 신뢰성 있는 전송을 책임지는 형태로 발전하게 되었습니다.
미국 국방부는 기존 네트워크 프로토콜 대신 TCP/IP를 ARPANET의 공식 프로토콜로 채택 하였으며, ARPANET은 추후 전 세계로 연결되어 현재의 인터넷으로 진화하면서 TCP/IP 프로토콜이 자리잡게 되었습니다.
In TCP Header
데이터를 패킷 단위로 쪼개는 것까지는 좋았는데 패킷이 사라지거나 훼손되면 어떻게 할 것인지, 패킷이 순서대로 도착한다는 것을 보장할 수 없는데 순서를 어떻게 확인할 것인지, 수신하는 쪽에서 처리할 수 있는 속도보다 송신 측이 패킷을 빠르게 보낸다면 어떻게 해야할지에 대한 고민을 할 필요가 있었죠.
이런 문제를 해결하기 위해 TCP에는 3-way handshake, 시퀀스 번호, ACK, 슬라이딩 윈도우같은 개념이 도입되었고, 이는 TCP 세그먼트의 헤더에 포함되어 있는 정보를 파악하도록 하여 문제점을 개선하게 되었습니다.
TCP 헤더에 어떤 정보가 있고 무슨 문제를 해결하기 위함인지 알아봅시다.
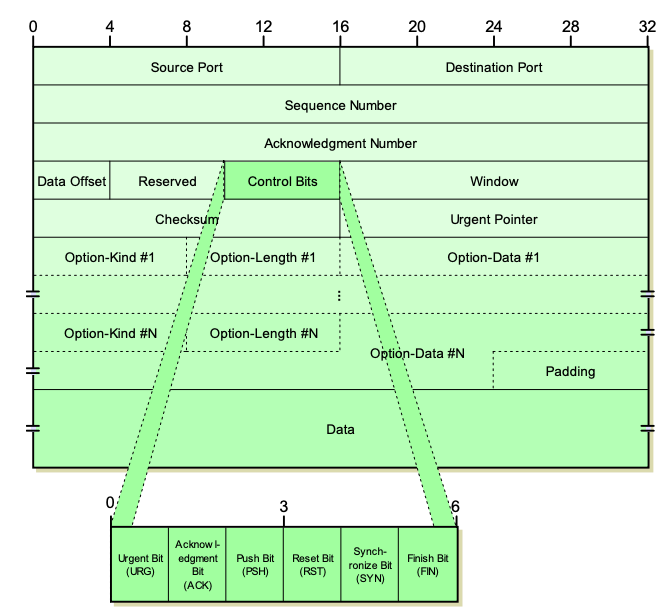
- Source Port & Destination Port
Source port와 Destination port는 각각 송신자와 수신자의 포트 번호를 나타냅니다.
쉽게 말해 출발지와 목적지에 대한 주소 정보인데, 이 주소를 판별하기 위해서는 IP 주소와 Port 번호가 필요합니다.
여기서 IP 주소는 OSI 7 Layer에서 한 계층 밑인 Network Layer에 있는 IP의 헤더에 담기기 때문에 TCP 헤더에는 필드가 없고 Port를 나타내는 필드만 존재합니다.
이 때, 포트 번호는 16비트로 구성되어 있어 ‘0부터 65535’까지의 값을 가질 수 있습니다.
- Sequence Number
Sequence Number는 전송하는 데이터의 순서를 의미합니다. 32비트를 할당받기 때문에 최대 값은 2^32-1(약 42억)까지 표현할 수 있어 중복될 가능성은 매우 적습니다.
네트워크 상황에 따라 세그먼트의 순서가 순서대로 오지 않고 중구난방으로 도착할 수 있는데, 수신자는 이 세그먼트의 순서를 파악하여 올바른 순서로 데이터를 다시 재조립합니다.
송신자가 최초로 데이터를 전송할 때, Sequence Number는 임의의 값으로 초기화하며, 이후 전송하는 데이터의 1 bytes당 Sequence Number가 1씩 증가시켜 데이터의 순서를 표현하다가 최댓값을 초과하게 되면 다시 0부터 시작하는 특징을 가집니다.
- Acknowledgment Number
Acknowledgment Number는 ‘승인 번호’로써 데이터를 받은 수신자가 예상하는 다음 Sequence Number를 의미합니다. Sequence Number와 같이 32비트로 할당받습니다.
연결 및 연결 해제 시 발생하는 handshake 과정에서 ‘상대방이 보낸 Sequence Number에 1을 더한 값’을 Acknowledgment Number로 만들어내지만, 실제로 데이터를 주고 받을 때는 ‘상대방이 보낸 Sequence Number + 수신한 데이터의 bytes’를 Acknowledgment Number로 만들어냅니다.
예를 들어 1MB(=1,048,576 bytes)의 데이터를 전송하는데, 이 데이터가 4개의 세그먼트로 쪼개져서 전송되었다고 상정하겠습니다.
이렇게 큰 데이터는 한 번에 전송할 수 없으므로, 송신자는 이 데이터를 여러 세그먼트로 쪼개(splitting)하여 조금씩 전송해야 합니다.
이 때 송신자가 한 번에 전송할 수 있는 데이터의 크기를 100bytes라고 가정했을 때, 송신자는 첫 전송으로 100bytes만큼 데이터를 전송하여 Sequence Number를 0으로 초기화합니다.
시퀀스 번호는 1bytes당 1씩 증가하여서 첫 bytes 묶음은 0, 두 번째는 1과 같은 순서가 매겨집니다.
그렇다면 전송을 통해서 0에서 99까지의 총 100개의 byte 묶음을 받았고, 그 다음 전송 때 받아야 할 Sequence Number는 100이 됩니다.
즉 승인 번호는 ‘다음에 보내줘야하는 데이터의 시작점’을 의미합니다.
- Data Offset
Data Offset은 전체 세그먼트 중에 ‘헤더가 아닌 데이터가 시작되는 위치가 어디인지 표기’하는 필드입니다.
오프셋은 32비트의 워드 단위를 사용하는데 이 말은 즉슨 32비트 체계에서 1 word는 4 bytes라는 뜻입니다.
Flags (control bits)
Flag는 9개의 비트 플래그로 구성되어 있는데, 현재 세그먼트의 속성을 나타냅니다. TCP 초기 설계 당시에는 6개의 플래그만 사용했지만, 인터넷이 복잡해지면서 혼잡 제어 기능과 같은 기능을 수행하기 위해서 다음에 설명할 Reserved 필드를 사용하면서 3개(NS, CWR, ECE)가 추가되었습니다.
각 플래그의 의미는 다음과 같습니다.
-
URG(Urgent): 긴급한 데이터가 포함되어 있음을 나타냅니다. 이 플래그가 설정되면 Urgent Pointer 필드가 유효해집니다.
-
ACK(Acknowledgment): 승인 번호 필드가 유효함을 나타냅니다. 이 플래그가 설정되면 승인 번호 필드가 의미를 갖게 됩니다.
-
PSH(Push): 수신 측에 데이터를 즉시 전달하도록 요청합니다. 이 플래그가 설정되면 수신 측은 버퍼링하지 않고 데이터를 애플리케이션에 즉시 전달해야 합니다.
-
RST(Reset): 연결을 재설정하는 데 사용됩니다. 이 플래그가 설정되면 현재 연결이 비정상적으로 종료되었음을 나타냅니다.
-
SYN(Synchronize): 연결을 설정하는 데 사용됩니다. 이 플래그가 설정되면 세그먼트가 연결 설정 요청임을 나타냅니다.
-
FIN(Finish): 연결을 종료하는 데 사용됩니다. 이 플래그가 설정되면 세그먼트가 연결 종료 요청임을 나타냅니다.
다음은 혼잡 제어 기능을 향상을 위해 도입된 3개의 플래그입니다.
-
NS(Nonce Sum): CWR, ECE 필드가 실수나 악의적으로 은폐되는 경우를 방어하기 위해 도입된 필드로, 혼잡 제어와 관련된 플래그입니다.
-
ECE(ECN-Echo): 해당 필드가 1이면서, SYN 플래그가 1일 때는 ECN을 사용한다고 상대방에게 알리는 의미. SYN 플래그가 0이라면 네트워크가 혼잡하니 세그먼트 윈도우의 크기를 줄여달라는 요청의 의미입니다.
-
CWR(Congestion Window Reduced): ECE 플래그를 받아서, 전송하는 세그먼트 윈도우의 크기를 줄였다는 의미입니다.
Reserved
이름 그대로 프로토콜의 발전 과정에서 사용할 것을 대비해(for future use) 예약된 필드로 모두 0으로 채워져 있으며, 3bits가 할당됩니다.
Window
Window 필드는 한 번에 전송할 수 있는 데이터의 양을 나타냅니다. 2^16-1(약 65,535) bytes까지 표현할 수 있습니다.
TCP는 오래된 프로토콜이라서(무려 ) 요즘 같은 고속 네트워크 환경에서는 64kb로는 부족한 경우가 많습니다.
그래서 bit를 shift하는 방식으로 윈도우 사이즈를 확장하는 방식도 고안되었으며, 얼마나 shift할 것인지는 WSCALE 필드를 사용하여 표기합니다.
Checksum
Checksum은 데이터 전송 혹은 저장 과정에서 발생할 수 있는 ‘오류를 감지’하기 위해 사용되는 값입니다.
TCP의 checksum은 16bits로 나눠서 차례로 더해가는 방법으로 생성됩니다. 어떻게 변조되었다는 것을 확인하는 걸까요?
데이터가 전송되는 동안 비트가 뒤바뀌거나 손실될 수 있는데, 이 때 수신 측에서 계산한 checksum 값과 송신 측에서 보낸 checksum 값을 비교하여 데이터의 무결성을 확인합니다.
예를 들어봅시다.
1101010100110101 (0xD535)
+ 1011010011110001 (0xB4F1)
-------------------여기서 두 수를 더합니다.
1101010100110101
+ 1011010011110001
-------------------
1 1000101000100110 (17비트 결과)여기서 자리수가 17비트가 되었으므로, 맨 앞의 캐리(1)를 따로 떼어내고
0000101000100110 (앞의 캐리를 뺀 16비트)
+ 1 (넘친 캐리)
-------------------
0000101000100111캐리를 다시 더해줍니다.
0000101000100111 (현재 합)
1111010111011000 (1의 보수 → 체크섬)여기서 1의 보수를 취하고 나면(비트 반전)
1111010111011000 (0xF5B8)위와 같은 이 데이터의 체크섬이 나옵니다.
이제 수신 측에서 검증을 해보겠습니다.
0000101000100111
+ 1111010111011000
-------------------
1111111111111111 (모든 비트가 1)모든 비트가 1이라서 정상 수신으로 판단되었습니다. 여기서 0이 하나라도 있으면 송신 측이 보낸 데이터에 뭔가 변조가 있었음을 알 수 있는 것이죠.
TCP는 checksum으로 오류를 검출했을 때 세그먼트를 즉시 폐기되고 응용 계층으로 전달하지 않고, 상황에 따라 재전송을 요청합니다.
Urgent Pointer
Urgent Pointer는 이름 그대로 긴급 포인터를 나타내며 16bits가 할당됩니다.
플래그에서 URG가 설정된 경우에만 유효하며 URG 플래그가 1이라면 수신 측은 이 포인터가 가르키고 있는 데이터를 우선 처리하게 됩니다.
Options
Options 필드는 TCP의 기능을 확장할 때 사용하는 필드로 가변적(variable)입니다.
때문에 수신 측이 어디까지가 header이고 어디서부터 데이터인지 알기 위해서 Data Offset 필드가 필요합니다.
데이터 오프셋 필드는 20 - 60 bytes의 값을 표현할 수 있다고 했는데, 아무런 옵션도 사용하지 않은 헤더의 길이, 즉 Source Port 필드부터 Urgent Pointer 필드까지의 길이가 20 bytes이고, 옵션을 모두 사용했을 때 옵션 필드의 최대 길이가 40 bytes이기 때문입니다.
데이터 오프셋 필드의 값이 5, 즉 20 bytes보다 크지만 TCP의 옵션을 하나도 사용하고 있지 않다면, 초과한 bytes 만큼 이 필드를 0으로 채워줘야 수신 측이 헤더의 크기를 올바르게 측정할 수 있습니다.
TCP에서 제공하는 options은 여러 가지가 있지만 대표적으로 WSCALE, ASACK가 많이 사용됩니다.
맺음
글이 너무 길어질 것 같아서 잘랐는데, 이후 글에서는 TCP Handshake와 혼잡 제어, UDP 대해서 이어서 다룰 예정입니다.
읽어주셔서 감사하고 잘못된 내용이 있다면 언제나 피드백 주세요.